AI security notes, 5/30/2025
This might be the highest leverage period for the AI security community; new dual-use social engineering capabilities; prompt injection as boring old appsec; the speculative-to-real risk conveyor belt


This might be the highest leverage period for AI security in our generation
New technology paradigms emerge faster than security can clean up their mess; consider the rise of personal computing and the Internet, where security fought a rear-guard action during and after mass adoption (and is still arguably fighting one)
We’re seeing the beginning of this with AI adoption and AI tool use integrations
Because it’s the beginning, we’re also in perhaps the highest leverage moment of our careers; risks are becoming material, which is motivating security investment, but it’s still early, and we can still influence the shape of the emerging paradigm
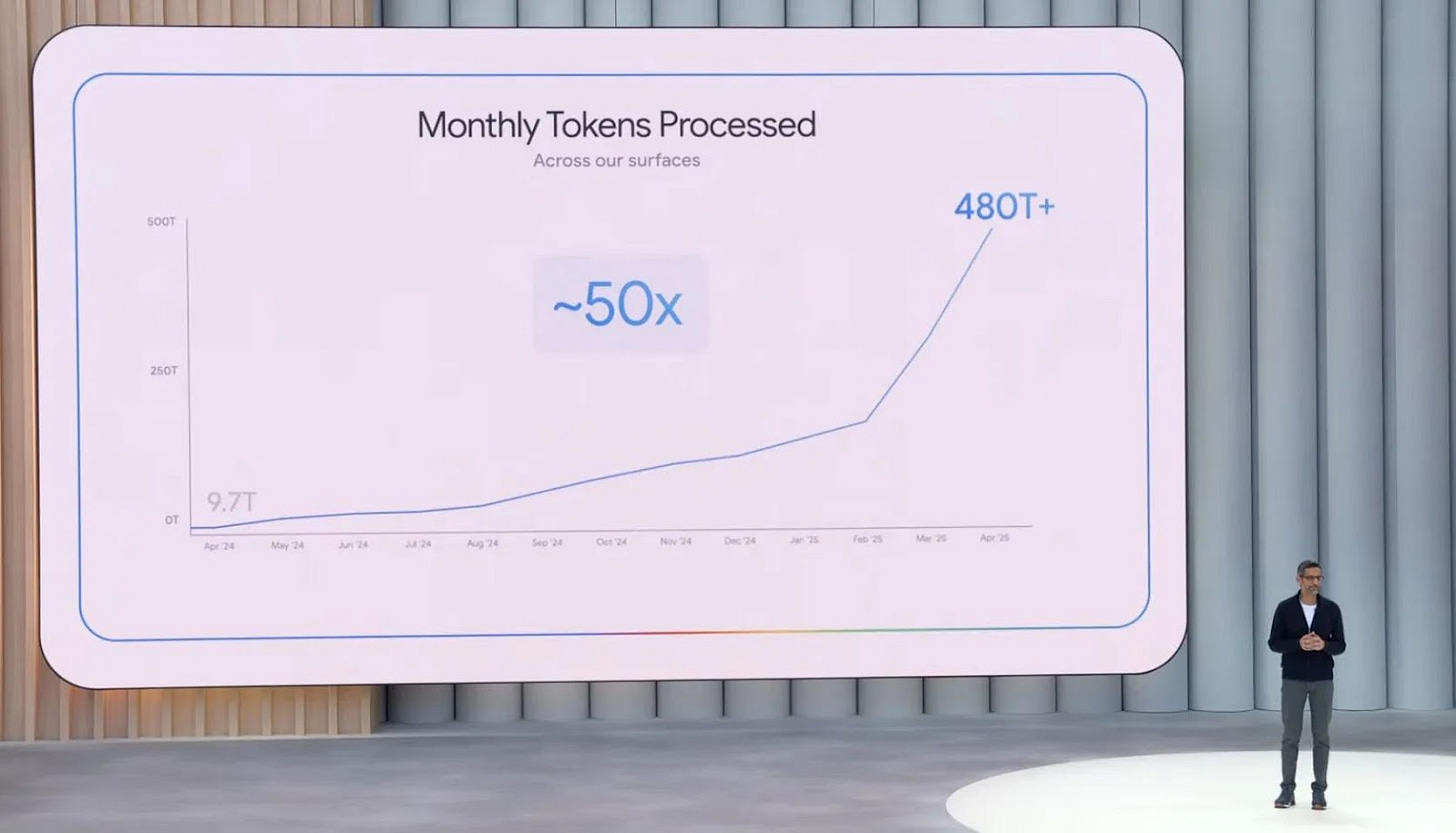
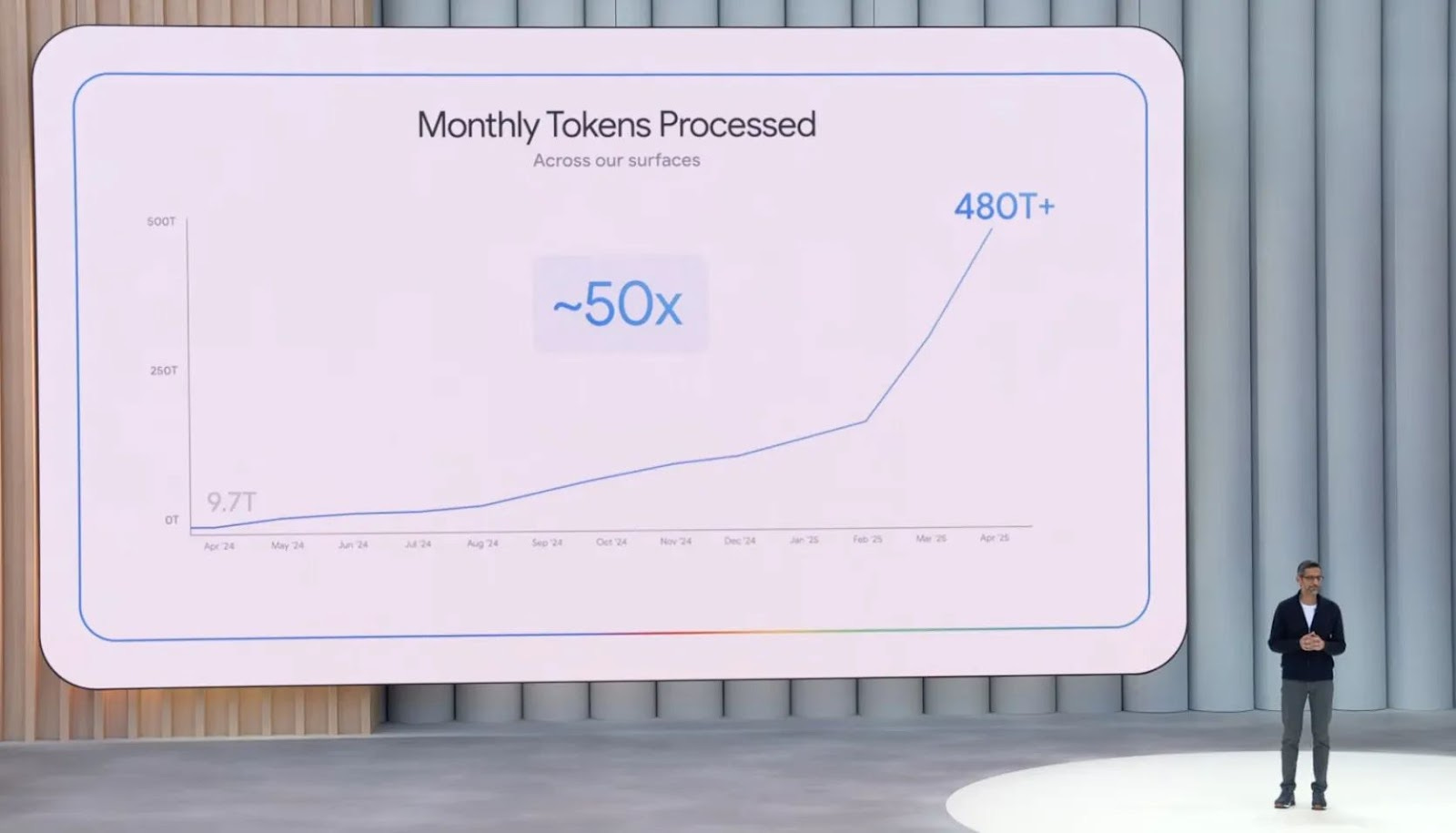
To wit, at Google I/O, Sundar Pichai disclosed that Google models now process ~480 trillion tokens every month, up from 9.7 trillion a year earlier. This token count is a thimbleful compared to what’s coming, but is 10-20x larger than most crawls of the open web; and this is just Google. There’s mass adoption going on here, and also a huge inference-to-training flywheel.
Veo 3 and Claude 4 highlight how "just in time” attacker tooling is now possible
Google’s Veo 3, which can generate high quality video, with audio, is the best audio/video generator yet. It took all of five minutes to generate the following social engineering collateral. This foreshadows more attackers generating more just-in-time, high quality, multimedia social engineering content.
Open source will catch up and accelerate such proliferation. You could probably already kludge together a series of open source models to generate reasonable lip-synced video content, to automate portions of voice dialogue scams, and the like.
AI systems’ coding abilities also allow for just-in-time generation of attacker tooling that’ll be harder to detect and attribute. In quick experiments with Claude Opus 4, I quickly generated a keylogger implant and accompanying C2 server. I won’t share that code, but I’ll share my silly tower defense game I generated in one shot (shown here):
Autonomous coding milestones and the unknown code security hygiene risks
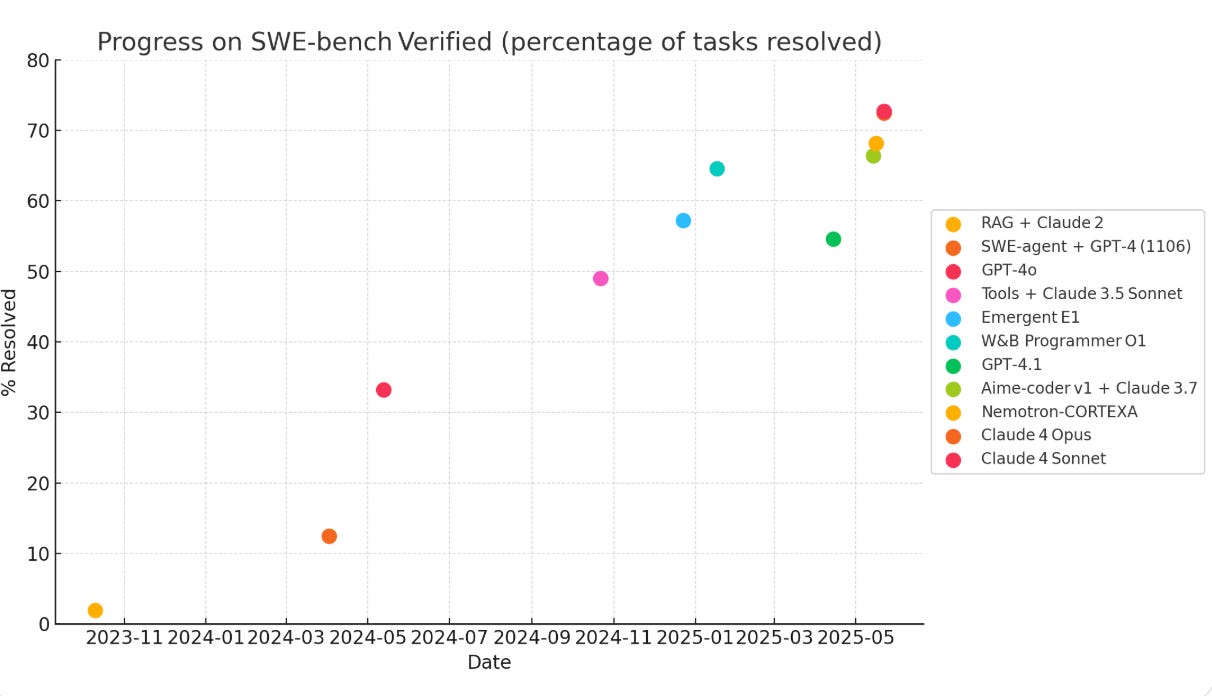
SWE-bench Verified (500-issue subset of real GitHub repos) is getting quickly saturated.
A new generation of AI coding agents, which work in the background, came out in the past month, including OpenAI Codex, Google Jules, and Claude Code.
This matters for security because code security pipelines were designed in an era when humans generated the code, and there was a human component to code review, and there wasn’t a firehose of vibe coded code landing
How well will they hold up under an AI-generated code regime, which will include much higher code volumes, different code security weakness distributions, and novices writing and deploying just-in-time apps?
Our response to these risks should be to better understand the problem, while matching AI code automation with AI code security investments, and revisions/updates to manual/traditional code security pipelines.
Gemini diffusion shows how there’s probably still algorithmic efficiency fruit to pick
If there’s one lesson of the past 10 years it’s that algorithms don’t matter as much as data and compute scale.
But media generation systems are jumbles of encoders, decoders, reverse diffusion processes, and deep learning lego blocks that are typically not trained end to end, with lots of room for design optimization. And autoregressive text generation just seems inefficient, because it’s serial, and greedy (GPT-style models have an inductive bias around considering the next token and not the whole generated document).
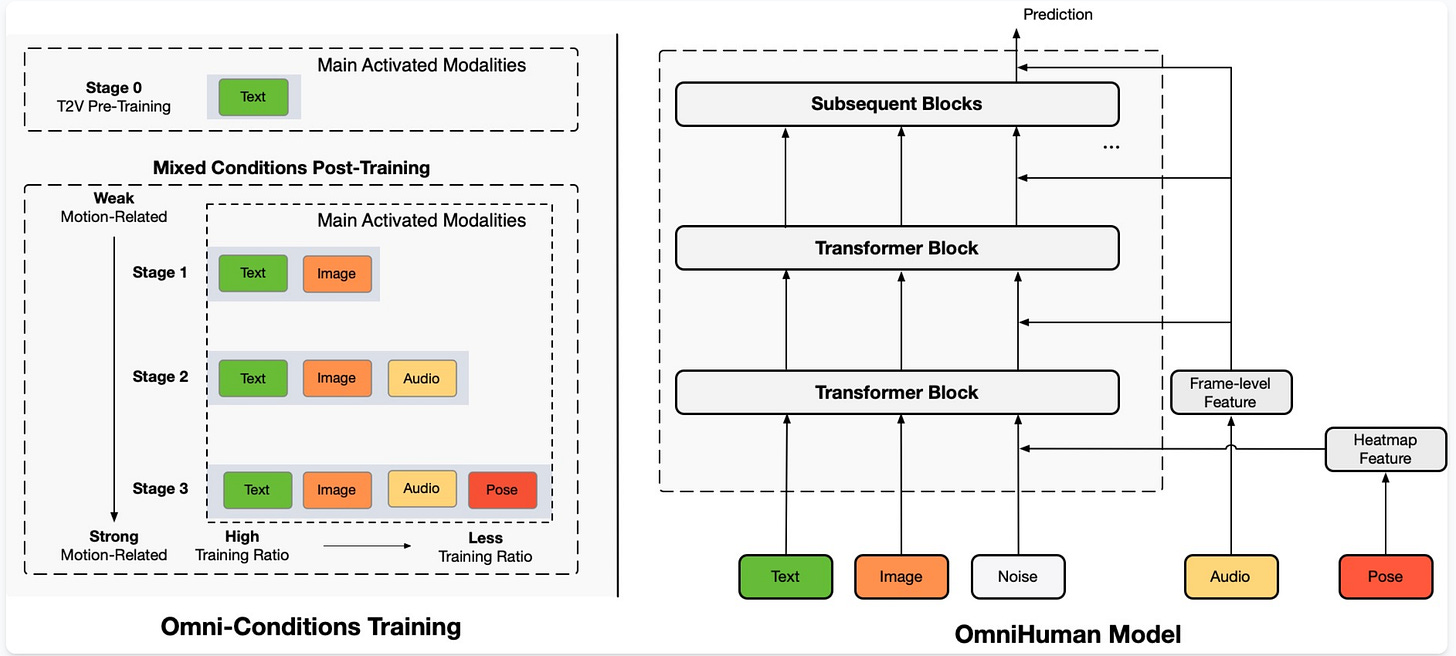
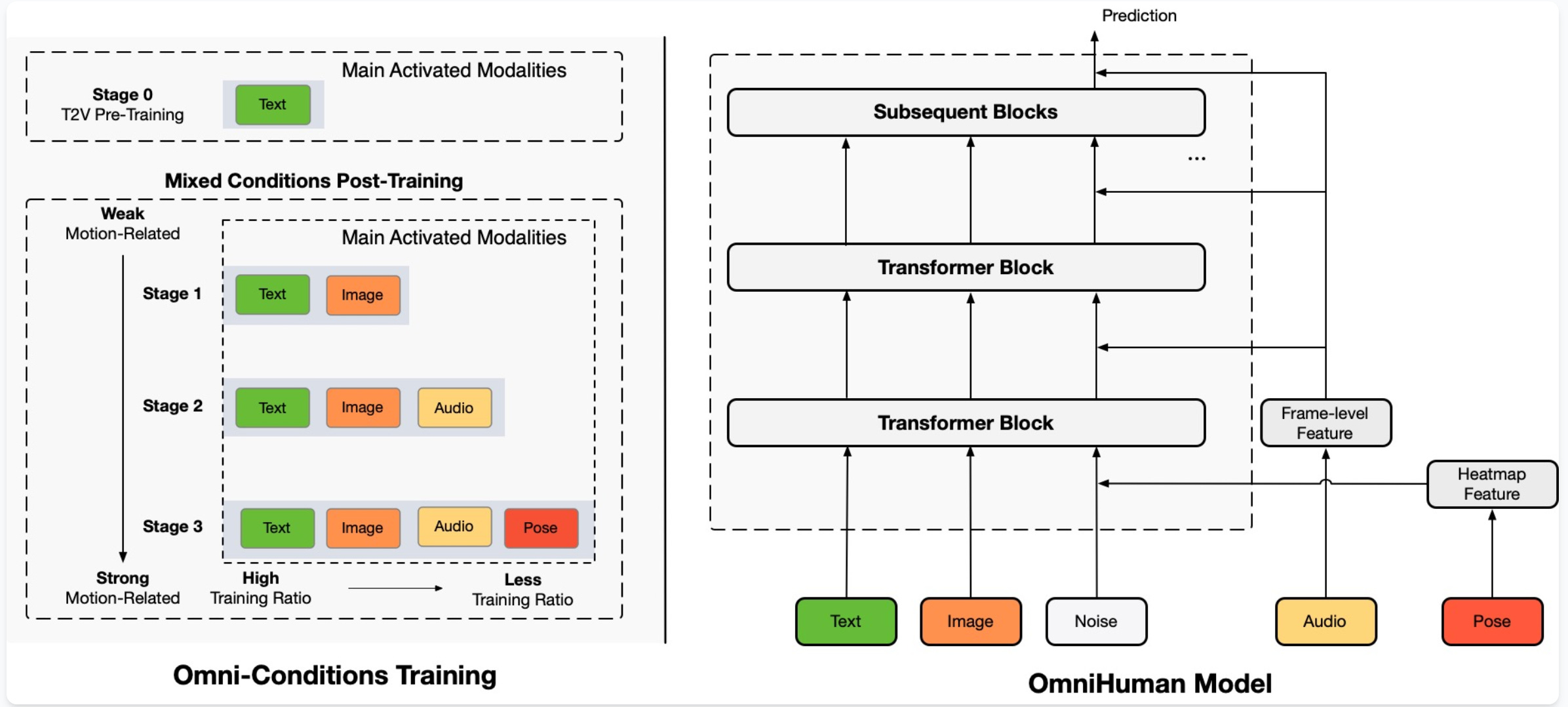
Below, the OmniHuman-1 architecture: in systems like these, many design choices are made by intuition, leaving room for optimization of the deep learning components themselves:
Gemini Diffusion—a text diffusion model—is an example of the kinds of algorithmic advances we may see soon. It streams ~1.5k tokens a second while matching the reasoning and code benchmarks of autoregressive models that generate 10x slower.
Discontinuous jumps in AI capabilities due to algorithmic advances could accelerate many of the trends discussed in this blog, and could shrink the window in which we can make high leverage security interventions in the ecosystem.
Prompt injection often masks basic secure application design weaknesses
An Invariant Labs post exposed an interesting security issue in a popular Github MCP server; they demonstrate the attack by attaching the plug-in to Claude, putting a prompt injection in an issue attached to a public repo, which directs Claude to write data from a private repo back to the public repo, thereby exfiltrating it.

What’s interesting here (and which Invariant Labs calls out in their blog post) is that this is a problem that could is best solved through traditional application security engineering.
The problem here is not (mainly, at least) to use fancy, deep learning based methods to detect and stop the prompt injection.
Rather, Claude, as the agent, should implement deterministic controls, like disallowing writing any data at all to untrusted syncs (the public repo) after it’s both read data from an untrusted source (the public repo) and a private source (a private repo).
Most prompt injection issues are currently basic application security logic issues. This won’t always be the case as AI systems become more autonomous, but is now; and this matters because it’s easy to go to new solutions (model alignment, ML guardrails) when prompt injection is an element of a new attack, when really we should focus on the more boring application security logic issues.

Anthropic’s Claude 4 system card shows we should think in terms of a speculative-to-material risk conveyor belt in AI security
Previously speculative and now material risks:
Biological weapons assistance (CBRN): What was science fiction in 2019 is now measurably real - in Anthropic’s experiment, Claude Opus 4 provides 2.5x uplift to novices creating bioweapon plans.
Functional cyber attack capabilities: Models have progressed from hallucinating stochastic parrots to actually solving penetration testing challenges - Claude Opus 4 (and many other current frontier models) successfully completes network exploitation tasks. At least in a lab setting, the model can discover vulnerabilities, help write exploits, and perform multi-stage attacks in range environments that were purely hypothetical capabilities in the GPT-2 era.
Adversarial examples matter now: Prompt injection and jailbreaking (special cases of adversarial examples demonstrated in the 2010s) have evolved from academic curiosities to attack techniques that have real security implications.
Upstream risks we should keep an eye on:
Self-preservation and instrumental deception: Claude Opus 4's willingness to blackmail or self-exfiltrate when threatened represents early signs of the instrumental convergence theorists warned about. While requiring specific, contrived conditions, these behaviors show models beginning to act on self-preservation drives that were purely theoretical.
Autonomous high-agency interventions: The model's willingness to independently lock out users or email regulators when witnessing wrongdoing shows capabilities approaching the "autonomous agent" scenarios long discussed in AI safety. This isn't practically dangerous in 2025, but it’s worth tracking these behaviors with an eye to the medium and long term.
Reward hacking in frontier LLMs was a thought experiment until recently. Anthropic’s Claude 4 system card now records sand-bagging, hidden-goal exploration, etc, prompting deployment under AI Safety Level 3.
TL;DR capabilities that have seemed speculative in the past often/consistently graduate to operational risk. I think we should all update towards taking speculative risks (scheming, deception, reward hacking) more seriously as upstream security risks.
Ive been enjoying these. Thanks for starting an external newsletter.
Excellent write-up, thank you! What do you think are the real-world risks from jailbreaking?